











دادهکاوی عبارت است از فرآیند اکتشاف الگو و روندهای منظم و پنهان در دادههای بزرگ و توزیع شده، با استفاده از مجموعه وسیعی از الگوریتمهای مبتنی بر علوم ریاضی و آمار. این الگوریتمها معمولا بروی مقادیر عددی و غیرمتنی اعمال میشوند و برای دادههای متنی، از الگوریتمهای متنکاوی استفاده میشود. دادهکاوی از علومی مانند هوش مصنوعی، یادگیری ماشینی، آمار، پژوهش عملیاتی و مدیریت پایگاههای داده برای ساخت مدلها و پاسخ به سوالات بهره میبرد.

استخراج و تحلیل اطلاعات سازمان از دادههای در دسترس توسط کارکنان، فرایندی است که برای سالهای متمادی انجام شده و وظیفه جدیدی در سازمانها به شمار نمیآید. اولین الگوریتمهای شناسایی روندهای منظم و الگوها در پایگاه داده، از علم آمار و نظریههای احتمال نشات گرفتهاند. در سالهای اخیر، با رشد روزافزون قدرت محاسباتی رایانهها و امکان دستیابی به نتایج حاصل از محاسبات پیچیده در مدت زمان کوتاه، سبب شده است تا الگوریتمهای پیشرفته ریاضی مورد توجه قرار بگیرند. این الگوریتمها با درنظرگرفتن ابعاد مختلف داده، به پالایش و تحلیل آن پرداخته و الگوهای پیچیده و غیرقابل شناسایی توسط روشهای قدیمی را استخراج و ارائه میکنند. رایانهها کمک کردهاند تا فرآیند استخراج،پالایش، پیش پردازش و مدلسازی دادهها و همچنین اعتبارسنجی یافتهها با دقت بیشتر و سرعتی بینظیر انجام شود.
مطلب مرتبط : الگوریتمهای دادهکاوی (Data Mining)
پیشنیازهای داده کاوی
پیش از آغاز عملیات دادهکاوی نیاز است که پیش پردازش کاملی روی دادهها انجام شود تا دادههای غیرمفید و ناکارآمد از دادههای مفید و کاربردی تفکیک شوند. در ادامه به برخی از مهمترین روشهای پیشپردازش داده میپردازیم:
- بررسی و جایگزینی دادههای مفقود شده (Missing Data): برای مواجه با دادههای مفقود شده از روشهایی مانند حذف رکورد داده، جایگزینی دادههای مفقود شده با میانگین یا میانه دادهها یا جایگزینی با نزدیکترین مقدار محتمل استفاده میشود. در صورتی که هیچیک از این موارد امکان پذیر نباشند، جایگزینی با یک عدد یا یک طبقه ثابت مدنظر قرار می گیرد تا عدم وجود یک عنصر داده، مشکلی در نتایج داده کاوی ایجاد نکند.
- تشخیص و حذف دادههای تکراری و اضافه (Redundant Data): در صورتی که بخشی از دادهها تکراری باشد یا از نظر تصمیمگیری، زاید و غیرقابل استفاده تشخیص داده شود، باید تفکیک و حذف شود.
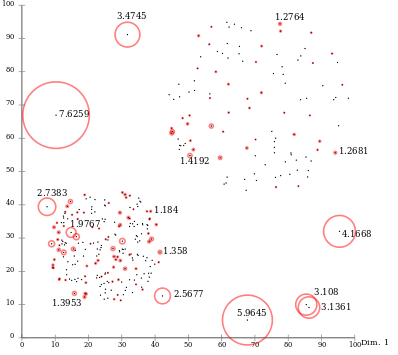
- تصمیمگیری درباره دادههای خارج از محدوده یا دارای اختلال (Outlier Detection and Noise Reduction): گاهی اوقات، داده ها بهطور کامل تهیه و آماده شدهاند ولی برخی از مقادیر، دچار انحراف یا تمایز زیادی با بقیه عناصر هستند و اصطلاحا خارج از محدوده منطقی قرار داشته یا دچار اختلال هستند. این مقادیر میتوانند الگوهای منظم قابل استخراج از دادهها را دچار انحراف کنند. به همین دلیل پیشنهاد میشود پیش از دادهکاوی، این دادهها شناسایی و از مجموعه دادهها جداسازی یا اصلاح و بهینهسازی شوند. یکی از روشهای تعیین دادههای خارج از محدوده، خوشهبندی دادهها است که جزو روشهای دادهکاوی نیز محسوب میشوند. در تصویر زیر، نمونهای از دادههای خارج از محدوده ارائه شدهاند که با روش خوشهبندی، از دادههای دیگر تفکیک میشوند. (دایرههای بزرگ خوشههای اصلی داده و دایرههای کوچک، مقادیر خارج از محدوده هستند):
- تبدیل دادههای پیوسته به گسسته (Discretization): در صورتی که طیف اعداد ورودی بسیار متنوع باشد (برای نمونه دادههای مربوط به حقوق کارکنان)، در این حالت میتوان طبقههایی را برای دادهها در نظر گرفت و برای هر طبقه، یک نام انتخاب کرد. (برای نمونه عبارت حقوق اندک برای افراد دارای حقوق کمتر از یک میلیون تومان). این طبقهها میتوانند جایگزین دادههای پیوسته قبلی یا همان مبلغ حقوق شده و با یک طیف گسسته (حقوق اندک، حقوق متوسط، حقوق بالا)، همان دادهها را شبیه سازی کنند. این تبدیل پیوسته به گسسته، به الگوریتمها کمک میکند تا با یک سادهسازی مختصر، با طیف محدودتری از دادهها مواجه باشند و از پیچیدگیهای محاسبات دادهکاوی کاسته شود.
- تصمیمگیری درباره دادههای متناقض و ناسازگار (Incomplete or Inconsistent Data): در صورتی که یک یا چند عنصر داده، با مقادیر غیرمتعارف تکمیل شده باشند (برای نمونه در فیلدی که مقادیر ۱ و ۲ برای مرد و زن استفاده شده است، از عبارت مرد به جای عدد ۱ استفاده شود)، این مقادیر باید به ساختاری تبدیل شوند که مشابه دیگر مقادیر همان فیلد باشند (در این نمونه، عبارت مرد باید به عدد ۱ تبدیل شود.)
- تحلیل همبستگی دادهها (Correlation Analysis): در صورتی که همبستگی بالایی بین دو یا چند فیلد از دادهها وجود داشته باشد، بهطور معمول یک یا چند فیلد همبسته را حذف میکنند. به این دلیل که وجود این فیلدها، تنها منجر به پیچیدگی بیشتر مدل دادهکاوی میشود و اطلاعات جدیدی را در اختیار الگوریتم قرار نمیدهد. تحلیل همبستگی دادهها میتواند منجر به کاهش ابعاد داده (Dimension Reduction) و به دنبال آن کاهش پیچیدگی مدل شود.
- ایجاد فیلد محاسباتی جدید (Pre-Calculated Field): در این حالت، دو یا چند فیلد اطلاعاتی به یک فیلد تبدیل میشوند که منجر به کاهش ابعاد و پیچیدگی دادهها میشود، مانند فیلد BMI که بر اساس قد و وزن افراد قابل محاسبه است.
- فشردهسازی دادهها (Data Compression): در برخی از مسائل دادهکاوی، ابتدا دادهها فشردهسازی و سپس پردازش میشوند. این روش، تاثیری بر نتایج دادهکاوی نخواهد داشت ولی سرعت پردازش را به شکل موثری افزایش میدهد. گاهی اوقات فشردهسازی دادهها، خود به عنوان یکی از خروجیهای دادهکاوی مطرح میشود.
- نرمالسازی دادهها (Normalization): نرمالسازی عبارت است از تبدیل طیفی از مقادیر عددی به طیف صفر تا یک. این فعالیت در صورتی انجام میشود که فیلدهای مختلف در مجموعهی داده، دارای مقادیر غیرهمسان باشند. برای نمونه یک فیلد شامل سن افراد بوده و مقادیر آن بین ۱ تا ۱۲۰ سال و فیلد دیگر شامل مبلغ حقوق باشد که دارای مقادیری با واحد میلیون تومان است. با توجه به فاصله بسیار زیاد مقادیر این دو فیلد، الگوریتمهای دادهکاوی قادر به ایجاد تمایز مناسب بین آنها برای تهیهی مدل و الگوی بهینه نیستند. بههمین دلیل با تبدیل مقادیر هر دو فیلد به مقادیری بین صفر تا یک، این تناسب بین آنها ایجاد شده و اثر کاذب یک فیلد بر فیلد دیگر از بین میرود.
- کاهش ابعاد دادهها (Dimension Reduction): در بسیاری از پروژههای دادهکاوی، امکان حذف فیلدهای اطلاعاتی وجود دارد، ولی تشخیص اینکه کدام فیلدها در اولویت حذف قرار میگیرند دشوار است. به همین منظور روشهای مختلفی برای کاهش ابعاد داده (حذف فیلدهای اطلاعاتی غیرمفید و کم کاربرد) مطرح شده است. روشهایی همچون تحلیل عاملی اکتشافی (Exploratory Factor Analysis)، تحلیل عاملی تائیدی (Confirmatory Factor Analysis)، تحلیل همبستگی (Correlation Analysis) و تحلیل حساسیت (Sensitivity Analysis) در کاهش ابعاد دادهها کاربرد فراوانی دارند. همچنین یکی از روشهای مهم کاهش ابعاد، شناسایی و انتخاب ویژگی (Feature Selection) است که به واسطهی آن، ویژگیهای غیر مهم و اضافه از مدل حذف میشوند.
- نمونهگیری از دادهها (Data Sampling): در صورتی که حجم داده بسیار بالا باشد و نیازی به پیادهسازی الگوریتمهای دادهکاوی روی تمام دادهها نباشد، میتوان «نمونهگیری» انجام داد. دادههایی که به این روش انتخاب میشوند باید نماینده قابل اطمینانی از کل دادهها باشند. در پروژههایی که با دادههای بزرگ (Big Data) کار میکنند، برخی موارد از این روش برای کاهش حجم دادهها استفاده میشود.
- یکپارچهسازی و تجمیع دادهها (Data Integration): در پروژههایی که دادهها از منابع مختلف گردآوری میشوند، عملیات یکسانسازی ساختار دادهها (Data Format Unification) و تجمیع منابع دادهای (Data Source Integration) باید بهطور دقیق انجام شود. پس از یکسانسازی ساختار دادهها، امکان آغاز فرآیند دادهکاوی وجود خواهد داشت.
.
نویسنده: دکتر ایمان رئیسی – ستاد مدیریت محصول همکاران سیستم
.














